

Output Cache & Response Caching
Achieving performance and reliability with cache

One of the most challenging things to do in software engineering is to make applications reliably fast. Throwing more hardware is not sustainable and scaling horizontally could become expensive very fast.
There are a few things you can do to accomplish this feat, output caching is one of them, if the client request the same data over and over again we could cache this at the middleware level and avoid any further processing in the server.
What is even better is, if the data does not change as often the server could instruct the client to cache that data on its end completely avoiding the need to request the data from the server. This will not only make the application faster because it does not need to wait for a response from the internet but also makes the servers lighter, more reliable and ultimately cheaper to run.
This is an amazing resource if you want to learn more about response caching (cache-control) by Jake Archibald
https://jakearchibald.com/2016/caching-best-practices/
This is a great video from Hussein Nasser explaining in detail Jake's post
Browser Caching Best Practices, When to use no-cache vs max-age without breaking your site
In .NET 7, Microsoft introduced a built in mechanism to use output cache which makes things simpler to implement than before. .NET 8 made it even easier, Microsoft offers libraries for memory caching and distributed caching such as Redis.
Here are some articles from Microsoft
Output Caching
This is an example on how to implement output caching and response caching in .NET 8 using Redis distributed caching.
https://github.com/ricardochaidez/ChaidezMotorCompany
The key implementation is install Microsoft.Extensions.Caching.StackExchangeRedis nuget package.
Configure Redis output cache
services.AddStackExchangeRedisOutputCache(options =>
{
options.Configuration = redisEndpoint;
options.InstanceName = redisInstanceName;
});.NET output cache would use StackExchangeRedisOutputCache configuration as the default IOutputCacheStore for storage.
Configuring output cache
services.AddOutputCache(options =>
{
options.AddPolicy(OutputCachePolicies.CARS,
new OutputCachePolicy(OutputCachePolicies.CARS,
duration: TimeSpan.FromSeconds(expirationSeconds)));
});
app.UseOutputCache();That is it, output caching is configured to use.
One handy way to organize output caches with different rules is to use output cache policies.
Here is an example to customize policies.
In this case I just wanted to create a policy where I could configure its name and TTL.
public OutputCachePolicy(string policyName, TimeSpan? duration)
{
_policyName = policyName;
_duration = duration ?? TimeSpan.FromHours(1);
}As you can see when configuring the output cache earlier, a name of the policy and the IOutputCachePolicy class was used.
In a controller API, you can decorate each endpoint with OutputCache, this is where creating policies comes into place, lets say one endpoint is acceptable to cache its data for 1 day but a different endpoint has a different requirement and could be cached for 7 days.
[OutputCache(PolicyName = OutputCachePolicies.CARS)]There is a default behavior that Microsoft implements, by default output caching follows these rules:
Only HTTP 200 responses are cached
Only GET or HEAD are cached
Reponses that set cookies are not cached
Reponses to authenticated requests are not cached
Another advantage of creating a customized policy is that you can override these rules to fulfill your needs. For instance, a secure API would have endpoints that require authentication. These endpoints would not be cached with the default policy.
Note: You have to be careful enabling caching for authenticated endpoints. You could expose data that users with elevated permissions have access to or other user specific data. One way to solve this problem is to use CacheVaryByRules. You can use a unique key for users with certain permission and users with default permissions. For example, inspect the user's list of permissions in their authentication token and get the hash of that list as the rule.
Response Caching (Cache-Control)
Similar to output caching, response caching is very easy to implement.
services.AddResponseCaching();
var expirationSeconds = configuration.GetValue<int>("Cache:CarsOutputCache:ExpirationSeconds");
services.AddControllers(options =>
{
options.CacheProfiles.Add(ResponseCacheProfiles.CARS,
new CacheProfile()
{
Duration = expirationSeconds,
Location = ResponseCacheLocation.Client,
NoStore = false
});
});
app.UseResponseCaching();Similar to output caching custom policies, you can create a custom profile for response caching.
This implementation does not cache anything in the server side, it instructs the client for how long the data is acceptable to be cached and how it should be cached (shared, private, etc).
To expand the capabilities of response caching you can also create an Action filter, add extra information such as eTag and expiration header
Similarly to output caching endpoint usage, we can decorate each endpoint with ReponseCache attribute with the profile name.
[ResponseCachingFilter]
[ResponseCache(CacheProfileName = ResponseCacheProfiles.CARS)]If the output cache needs to be deleted, dependency injection can be used to pass the IOuputCacheStore (in this case it would be the stack exchange redis configured) and evict the by tag (also configured in the custom policy created earlier)
public async Task<IActionResult> Delete(CancellationToken cancellationToken)
{
await _outputCacheStore.EvictByTagAsync(OutputCachePolicies.CARS, cancellationToken);
return NoContent();
}Client side caching
What is cache-control?
As explained in this article, In a nutshell, when someone visits a website, their browser will save certain resources, such as images and website data, in a store called the cache. When that user revisits the same website, cache-control sets the rules which determine whether that user will have those resources loaded from their local cache, or whether the browser will have to send a request to the server for fresh resources.
This is what clients see when they call endpoints with response caching configured.
They see cache-control headers with all the information needed for them to cache data.
The first time the client calls the endpoint, it will get a HTTP 200 OK with the data and response headers with cache-control directives such as max-age, this means the amount of seconds this particular data can be cached for in the client side, other directives such as "must-revalidate, private" etc. You can learn more about cache-control directives here.
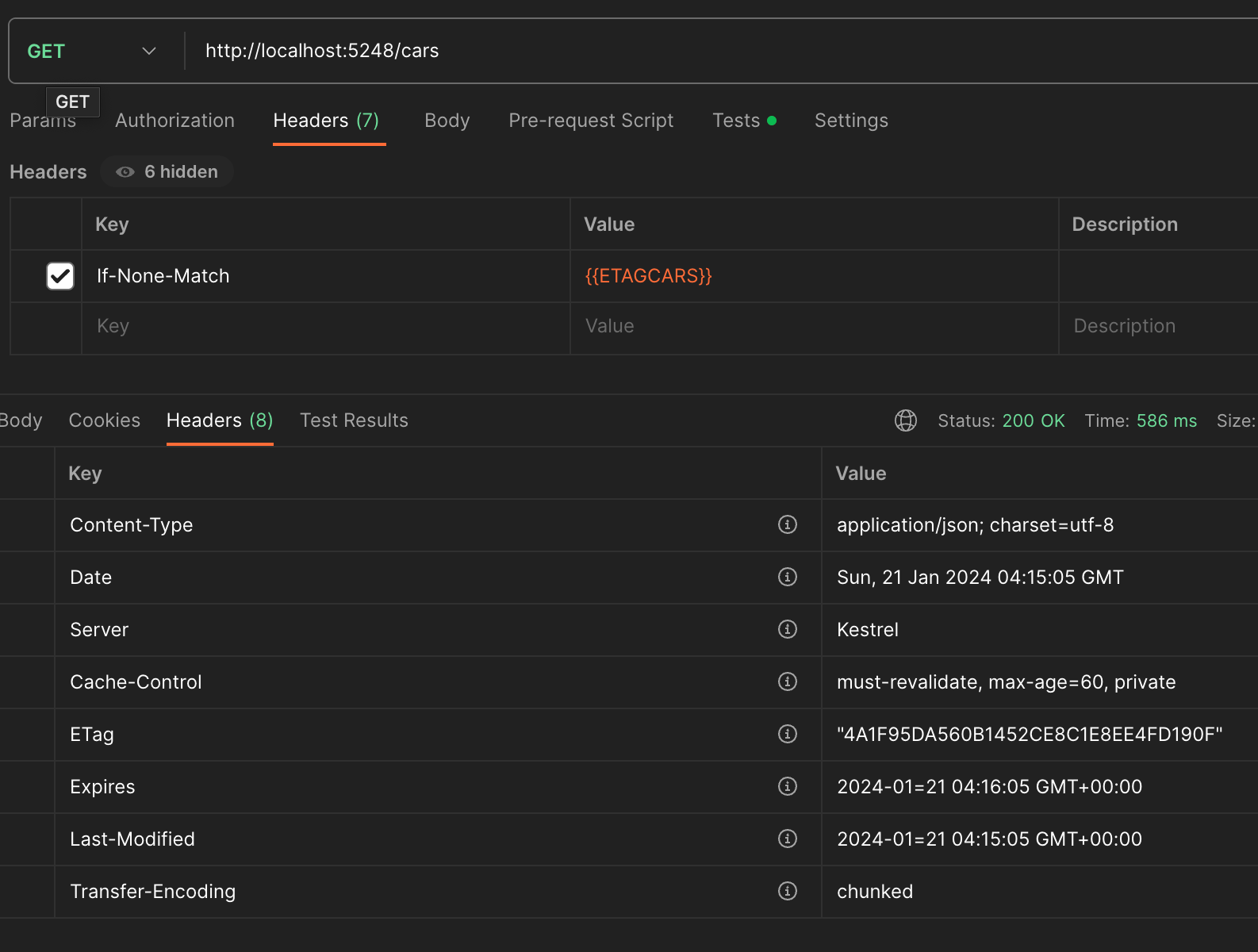
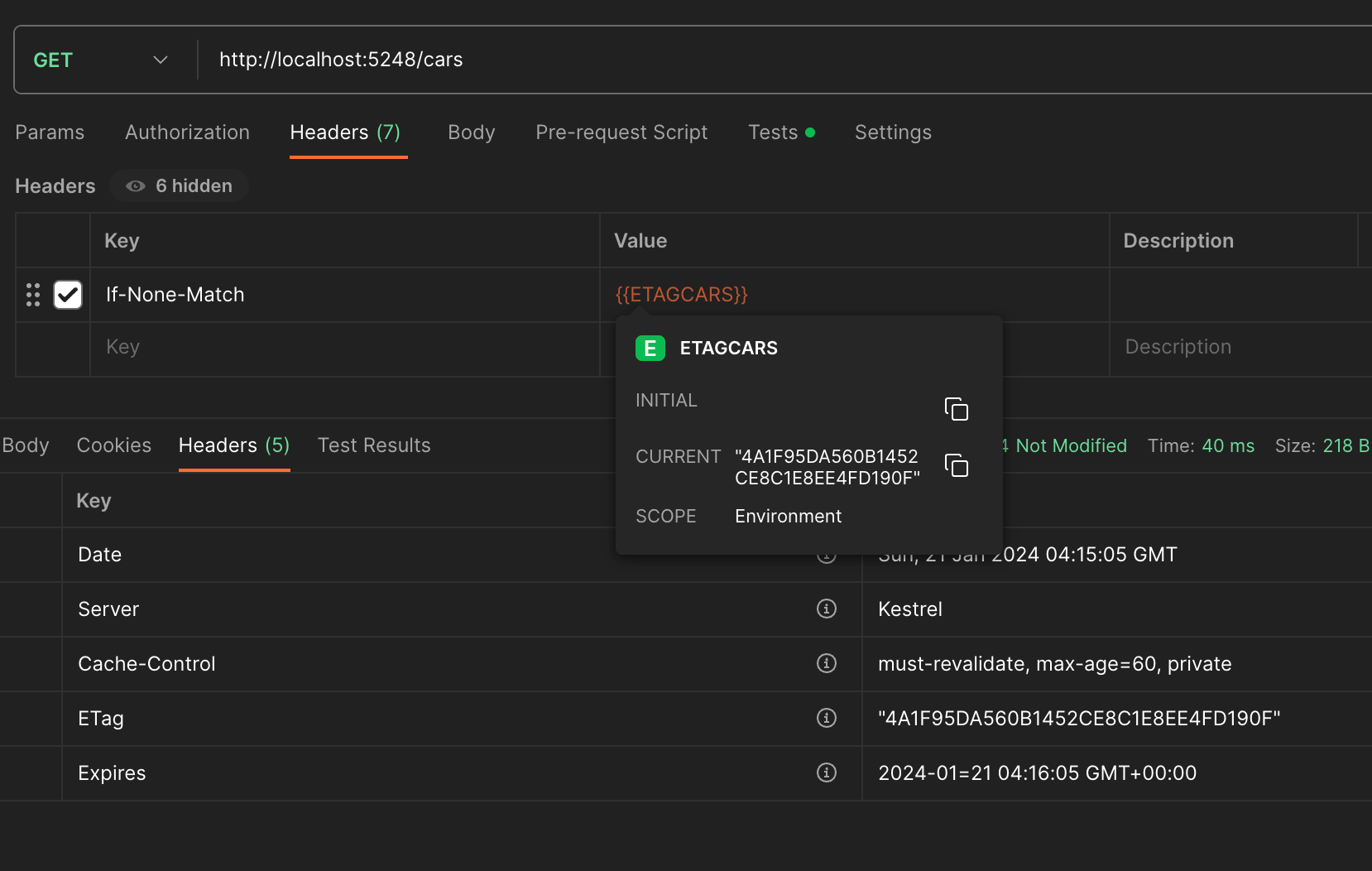
Etag is useful when the client calls the same endpoint before the expiration time, if the request contains header "If-None-Match" with the etag value from the previous response, the API will return a HTTP 304 Not Modified if the data is still the same.
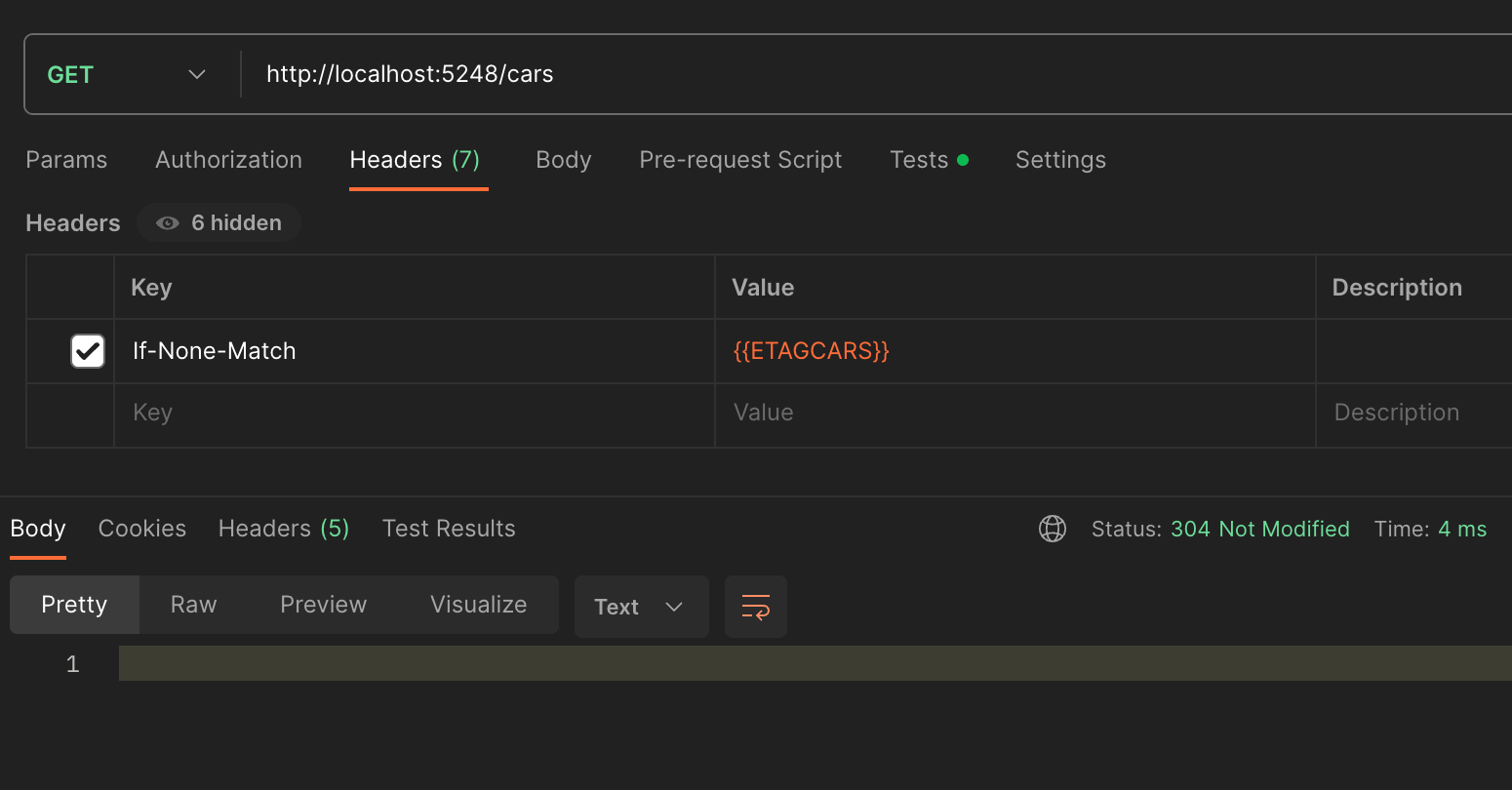
As you can see 304 response contains an empty body. The purpose of this response code is to tell the client that the data it already has is up to date saving bandwidth.
Importance of performance
In this example I am running this locally, the best case scenario. You can see that the first time there was a call to the endpoint, the backend needed to go and retrieve the data directly from the source (this could be a database, file storage, etc). In the example above, it took 586 ms, the second time, the data had been cached and only took 40 ms, it can get as fast as 4 ms depending on the speed of the client.
This small improvement in latency might not seen a big deal but there are several studies of importance of latency and user engagement/revenue.
https://www.gigaspaces.com/blog/amazon-found-every-100ms-of-latency-cost-them-1-in-sales
There is not one size fits all implementation for this, each application and each endpoint is unique and serves different type of data. Know your data and fine tune caching as needed to get the most benefits from it.